The science of multi-model AI collaboration
Using multiple AI models in parallel is the single most effective way to improve the depth, accuracy, and nuance of AI-assisted academic writing.
The single-model blind spot
Every large language model (LLM) is a product of its unique training data, architecture, and optimization goals. This means each model has inherent biases, knowledge gaps, and stylistic tendencies. Relying on a single model is like consulting only one expert—you inherit their perspective, complete with its limitations.
For example, GPT models from OpenAI are often trained for broad knowledge coverage and clear, direct instruction-following, making them excellent generalists. Claude models from Anthropic are calibrated for more cautious, source-grounded reasoning, often explicitly stating their uncertainty, which is valuable for academic rigor. Gemini models from Google are designed with deep integration into real-time information and multimodal capabilities, giving them an edge in surfacing recent developments. Using only one of these means you're only getting one slice of the pie.
A 2024 evaluation from the Stanford Center for Research on Foundation Models highlighted this divergence. On a set of factual questions, GPT-4 and Claude-3 disagreed in over 28% of cases. Crucially, in the set of disagreements, neither model was consistently correct. This starkly illustrates the risk: when you rely on a single model, you are implicitly accepting its blind spots, its errors, and its stylistic tics as your own, embedding them directly into your draft.
What "cross-validation" means in academic AI use
In academic research, particularly in systematic literature reviews, cross-validation is a cornerstone of rigor. Multiple independent reviewers assess the same body of literature to mitigate the bias of any single reviewer. The same principle applies directly to the use of AI in academic writing. By querying multiple models with the same prompt, you are performing a form of conceptual cross-validation, surfacing insights and identifying weaknesses that any single model would miss on its own.
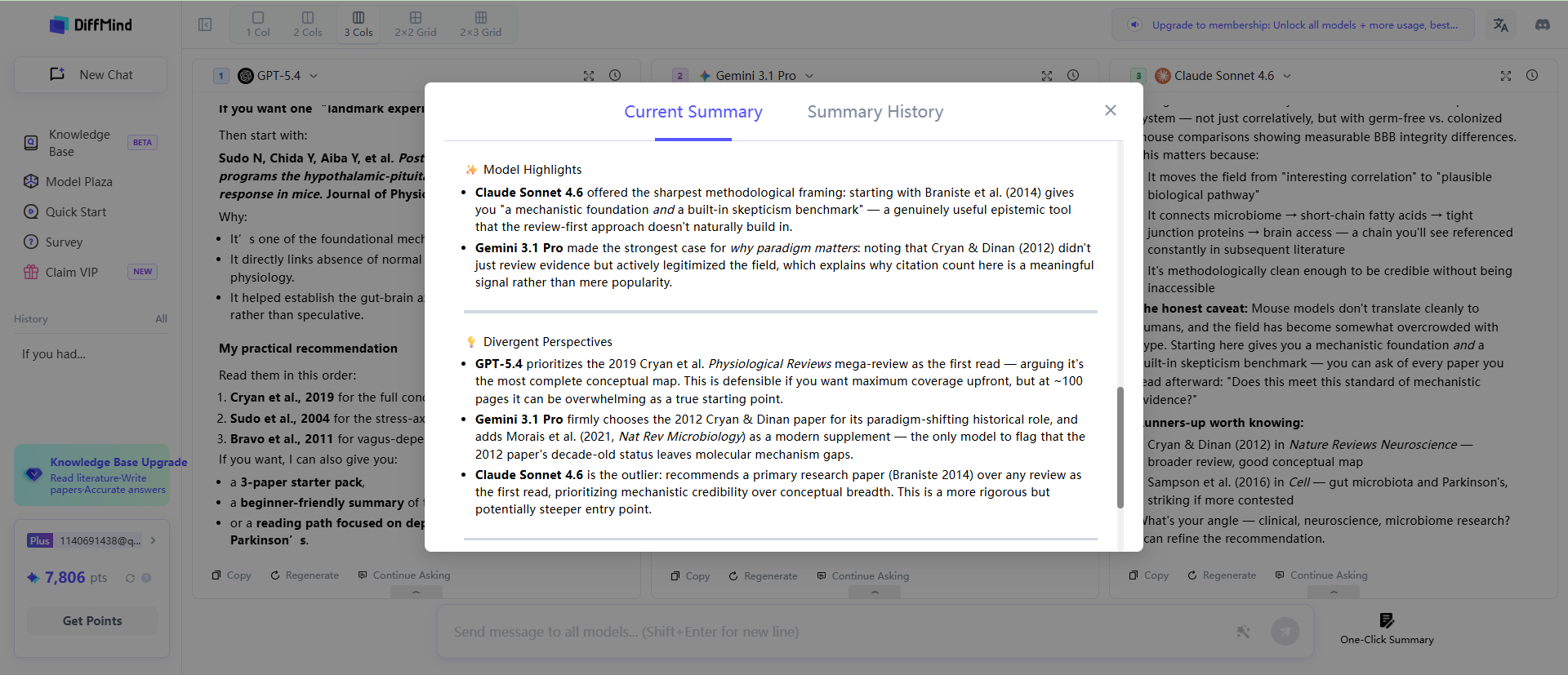
This process hinges on the concept of "response divergence." When all three models provide similar answers, it signals a high degree of confidence in the information—a point of convergence. However, the most valuable insights often lie in divergence. When GPT, Claude, and Gemini disagree on a fact, a theoretical interpretation, or a methodological justification, it acts as a critical flag. This divergence often points directly to contested claims, ongoing debates, or nuanced areas within the academic literature—precisely the kind of sophisticated engagement that elevates a paper from a simple summary to a critical analysis.
Research into ensemble methods in natural language processing confirms this. Studies have demonstrated that combining the outputs of several models consistently outperforms any single best-performing model on knowledge-intensive question-answering tasks. For a student, this means a multi-model approach is not just about catching errors; it's about actively seeking out the complex, high-value areas of a topic.
The compounding effect of model diversity
The benefits of using multiple models are not merely additive; they are compounding. One of the most significant advantages is a dramatic reduction in factual errors and "hallucinations." Quantitative studies have shown that ensemble methods can reduce hallucination rates by 40-60% compared to single-model outputs in factual recall tasks. This is because different models exhibit different failure modes.
For instance, GPT might confidently invent a citation to a plausible-sounding but non-existent academic paper. Claude, with its more cautious calibration, might avoid inventing a source but could understate a valid finding by hedging excessively. Gemini, while excellent at pulling recent data, might occasionally miss the broader context from earlier in a long document. By triangulating their responses, you create a powerful error-checking system. A hallucinated citation from GPT is unlikely to be replicated by Claude or Gemini, immediately flagging it as suspect. This process significantly raises the quality floor of your initial draft, ensuring the foundation of your argument is more robust from the very beginning.
| Approach | Time per query | Models consulted | Synthesis | Hallucination risk |
|---|---|---|---|---|
| ChatGPT alone | 2 min | 1 | None | High |
| Manual multi-tool | 30-45 min | 3 | Manual | Medium |
| DiffMind workflow | 3 min | 3 | Automatic | Low |
Why manual multi-model use is impractical for students
While the benefits of a multi-model approach are clear, the manual execution is prohibitively cumbersome for most students working under tight deadlines. The typical manual workflow involves opening three separate browser tabs for ChatGPT, Claude, and Gemini. You must then copy and paste the same prompt into each one, wait for each to generate a response, and then begin the painstaking process of reading three potentially long and dense outputs. The cognitive load is immense: you have to hold all three responses in your working memory, manually identify points of overlap and divergence, and then synthesize the key insights into a coherent new paragraph or section.
This entire cycle can take anywhere from 30 to 45 minutes for a single, complex research query. When writing a 10,000-word dissertation, this simply isn't a scalable strategy. The friction is so high that even students who understand the value of cross-validation quickly revert to the path of least resistance: using a single AI tool. The result is that the most effective method for producing high-quality, nuanced AI-assisted work remains an exception rather than the rule.
This is the problem DiffMind was built to solve. Our design philosophy is centered on eliminating this friction. We automate the entire workflow: parallel querying sends your prompt to all three models simultaneously; the side-by-side display makes comparison effortless; and one-click synthesis performs the heavy lifting of merging insights. By transforming a 45-minute manual chore into a 3-minute integrated workflow, DiffMind makes multi-model collaboration the default, not the exception, for serious academic work.